how ZFS organizes its data
What is different about ZFS?
This is unusual as these tasks are often not performed together, providing more control to ZFS in organizing the entire server (this can be described as part of ZFS's "software-defined" nature). As a result, ZFS's software-defined nature leads to unmatched robustness and is one factor that leads to ZFS being widely considered one of the premier choices for storage servers.
ZFS handles data integrity better than any other filesystem. ZFS uses a robust implementation of checksumming to prevent errors from occurring. This prevents bit-rot, data corruption, phantom reads/writes, and many other errors that are impossible to detect for most filesystems. It is recommended to give ZFS direct access to your drives without a hardware RAID controller, as ZFS can efficiently manage RAID on the software level. ZFS RAIDz (or mirrors) can detect silent data corruption and automatically correct errors, does not suffer from the write hole error, and is generally faster than a RAID-5. The elite-level integrity of ZFS makes it an excellent choice for many data-storage applications.
This article introduces beginners to how ZFS's data-storage hierarchy is organized, not providing a complete detailed description of every aspect of a ZFS system.
What is a device in ZFS?
What is a vdev?
Vdevs take one or more real devices and link them into a single unit (a single vdev). So, for example, you could have 4 HDDs within your server, which you link together within ZFS to create a single storage vdev.
A storage vdev will generally contain several actual disks arranged into a software-based RAID array. This will provide redundancy so that no data will be lost when a disk fails – a key factor for storage systems.
How can you arrange your vdevs?
- RAIDz1
- RAIDz2
- RAIDz3
- Mirror
- Single-device
What is RAIDz?
Check out this article on how ZFS RAIDz compares to typical RAID levels. In general, the number beside the RAIDz will dictate how many device failures it can suffer before losing the vdev. This is achieved by storing parity data in addition to any real data stored in the vdev. Then, when device failure occurs, parity data from the other devices are used to rebuild.
For example, if you had those 4 HDDs (4 devices) within your server and configured them into a RAIDz1, you would have a single vdev which can survive the failure of one drive before any data in the vdev is lost. This is handled through the software of ZFS, contrasted by a hardware RAID controller in many traditional servers.
What is a ZFS mirror vdev?
For example, if you had 4 HDDs within your server, you could configure your mirror vdev so that data from one device is replicated to all the others – then, even if three disks failed, your data and vdev would still be fine. Alternatively, if you set up two mirror vdevs, each containing two devices (HDDs), you could sustain a drive failure on either of them without data loss, but if two drives from the same vdev were lost, the data within would be destroyed.
What is a single-device vdev?
In addition to storage vdevs, there are special types of vdevs. These can also be arranged in any of the topologies above.
What are the special types of vdevs?
- LOG
- CACHE
- SPECIAL
CACHE vdev (usually called the L2ARC) is a read-cache. Reads are cached in RAM (L1ARC or simply ARC), but adding an L2ARC allocates storage space (generally on fast media like SSDs or Optane NVMe drives) for additional caching capacity to improve read performance on frequently accessed files. This can provide a negligible to large impact on performance depending on the types of files stored on the ZFS server.
For more detailed information on how ZFS caches data, check out this article on ZFS caching. In general, ZFS offers a lot of robustness in how you wish to tailor your systems caching to your use case – another area where being "software-defined" aids ZFS's robustness.
SPECIAL vdevs store metadata for ZFS systems. Special allocation class vdevs can provide a strong performance increase by using SSDs as your devices to quickly fetch file metadata within your zpool (the performance benefit will depend on the use case). The required size of your metadata vdevs will depend on your size of storage vdevs. These can be especially useful for applications with a heavy metadata workload, such as the VEEAM backup repository.
What is a Zpool?
One ZFS system could contain multiple zpools, and each zpool can hold multiple vdevs, but each vdev can only exist within one zpool. Likewise, each device can only exist within one vdev — each vdev is "owned" by the pool and can only exist within.
Within your zpools, you can create datasets which are analogous to regular directories. ZFS datasets allow some extra ZFS-specific features, like easy replication to other zpools and configurable record-size relative to other datasets on the zpool. Datasets are an excellent tool for optimizing mixed workloads living on the same zpool.
There is no redundancy provided at the zpool level. As the previous section shows, redundancy is achieved at the vdev level. If storage or special vdev fails, the entire zpool will be lost. Therefore, it is important to have a well-planned [device-vdev-zpool] hierarchy that doesn't create an unnecessary risk of data loss. Your zpools are only as redundant as the least redundant (storage or special) vdevs within.
This is generally not the case with a CACHE or LOG vdev failing, as they only contain caches of data which should exist on storage vdevs within the zpool, which prevents the entire pool from being lost.
However, it is possible to lose unwritten data if a power outage occurs before the data is transferred from the CACHE vdev onto a storage vdev. This will not fail the entire zpool because the data within the pool is still consistent with the preexisting state of the system — it is just not updated to reflect the data on the cache.
LOG vdev failure will not result in any data being lost, as all data on the L2ARC is stored within the pool. It simply keeps a cache of the most commonly accessed data to improve performance.
In the case of CACHE or LOG vdev failure, your zpool will be fine. In the case of storage or special vdev failure, your pool will be lost. Remember to implement the correct level of redundancy to give adequate protection against failures based on system size and application.
What is a Hotspare?
Hotspares are incredibly useful in providing uptime and safety in the event of failures, especially if IT admins cannot always be on-site immediately to replace failed drives.
What are ZFS Datasets?
For example, you could create a Zpool, then create datasets in the Zpool for client data, user data, archived data, and so on.
One common application of datasets is using one specifically for Samba file sharing.
Compared to traditional partitioning, datasets streamline the management process and are easily scalable.
Datasets are highly customizable and can be tweaked to suit the needs of each dataset. For example, compression, mount point, and access-control settings can be set on each individual dataset.
In summary of how ZFS organizes its data…
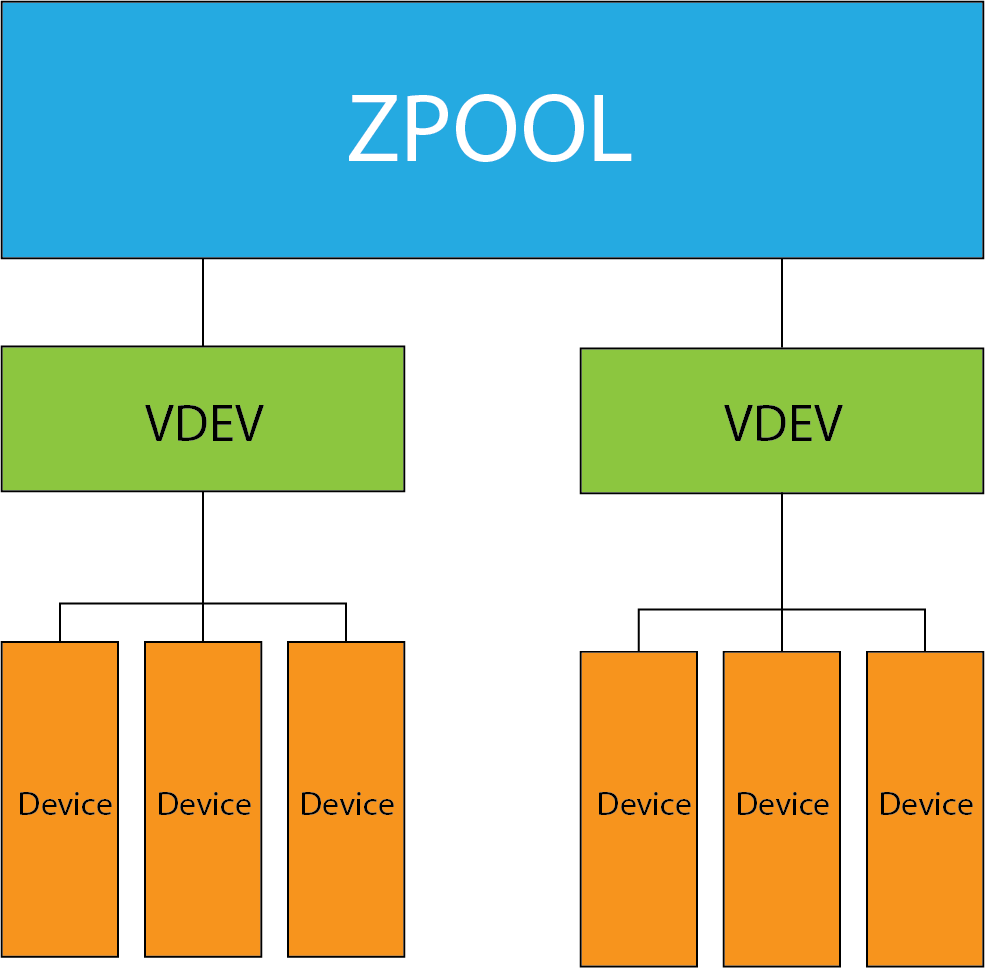
ZFS’s data-storage structure is in the form of:
At the top are zpools, which contain one or more — vdevs, which contain one or more — devices.
ZFS servers can contain multiple zpools, but each zpool has sole possession of any associated vdevs, which have sole possession of any real devices within.
Redundancy is implemented at the vdev level. Therefore, it is vital to intelligently plan the structure of your system based on your application's acceptable level of fault tolerance, performance, and storage efficiency.
Next Steps?
If you are interested in enterprise-grade ZFS storage systems, with end-to-end support, open-platform hardware, and years of real-world experience/ testing to back them up – 45Drives offers the ideal solution.
If you are unsure what ZFS solution best suits your needs, this questionnaire can help point you towards what will best fit your requirements.
If you would like to browse the hardware options 45Drives offers, the 45Drives’ products page can provide a full breakdown.
Contact us to discuss your storage needs and to find out why the Storinator is right for your business.
Contact 45Drives