When designing storage infrastructure, having redundancy is absolutely critical as an insurance policy against inevitable failures. However, redundancy comes with a trade off in storage efficiency, which increases your costs. For large infrastructure, a few cents difference in cost per TB can result in significantly higher total storage costs.
As a result, Erasure Coding within Ceph is highly appealing. We’ve discussed the differences between Erasure Coding and Replica in other blogs and videos before, but as a primer:
Erasure Coding is similar to a parity-based RAID array. A number of data chunks (K) and parity chunks (M) are created for each object. Replica, on the other hand, simply creates additional copies of a given object, similarly to a mirrored RAID array. This generally means that Erasure Coding has higher storage efficiency than Replica, calculated as k/(k+m).
For instance, using an example of 6+2, you’d get 75% storage efficiency — 6 chunks of data, out of 8 total chunks recorded. Compared to a three replica where you would have 33% efficiency, with 1 chunk of data out of 3 total recorded chunks.
These efficiency numbers are generally correct, except for one often overlooked problem: write amplification.
The minimum allocation size within data storage is essentially the smallest unit that a piece of data can be written in. Prior to Pacific Ceph, this value defaulted to 64kb. This minimum allocation unit poses a problem for certain workloads, especially those that operate on many small files.
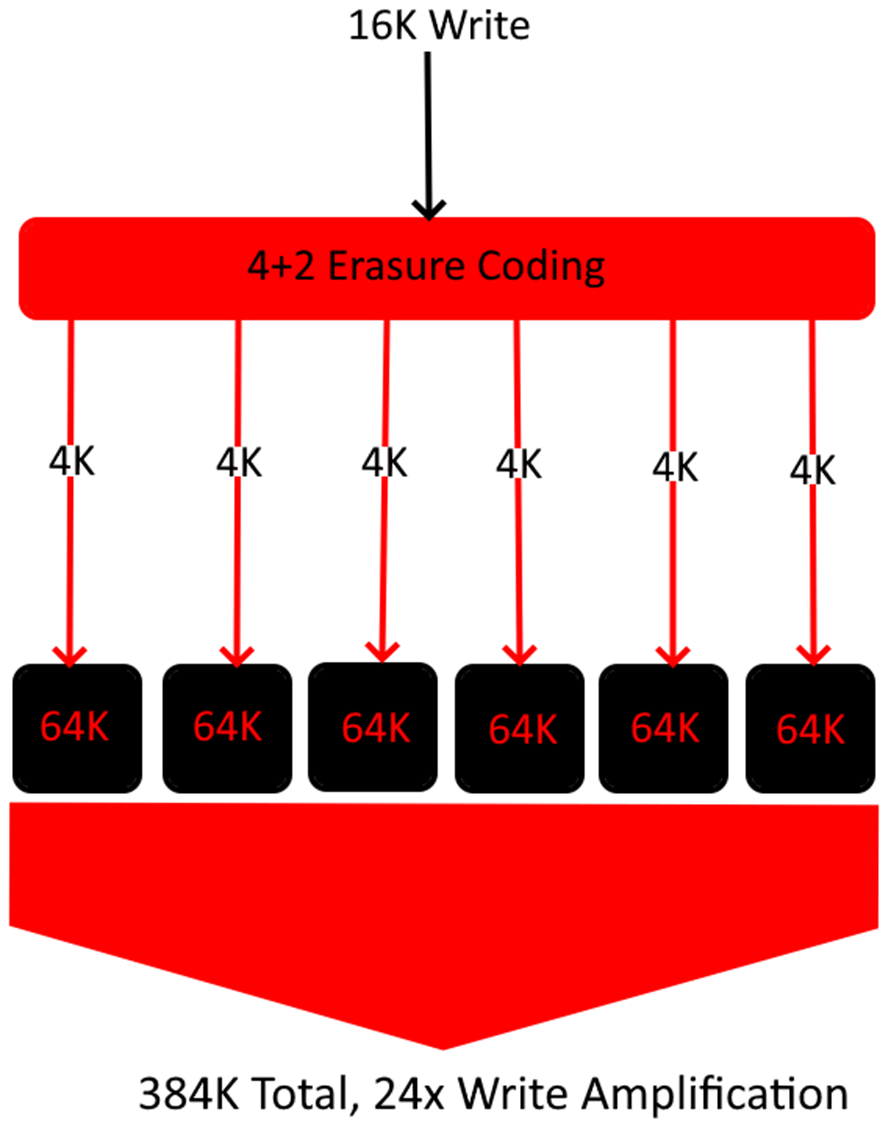
To visualize this, let’s think of a 4+2 erasure coding pool with an incoming write of 16kb.
In the above example, a single 16K write ends up exploding 24 times in size as each chunk needs to be written to disk at a minimum of 64K. This results in a ~4% total storage efficiency on this particular object. If your workload primarily consists of 16K objects, then this can very quickly negate any advantage your EC profile is providing. Below is a 3 Replica example using the same file size.
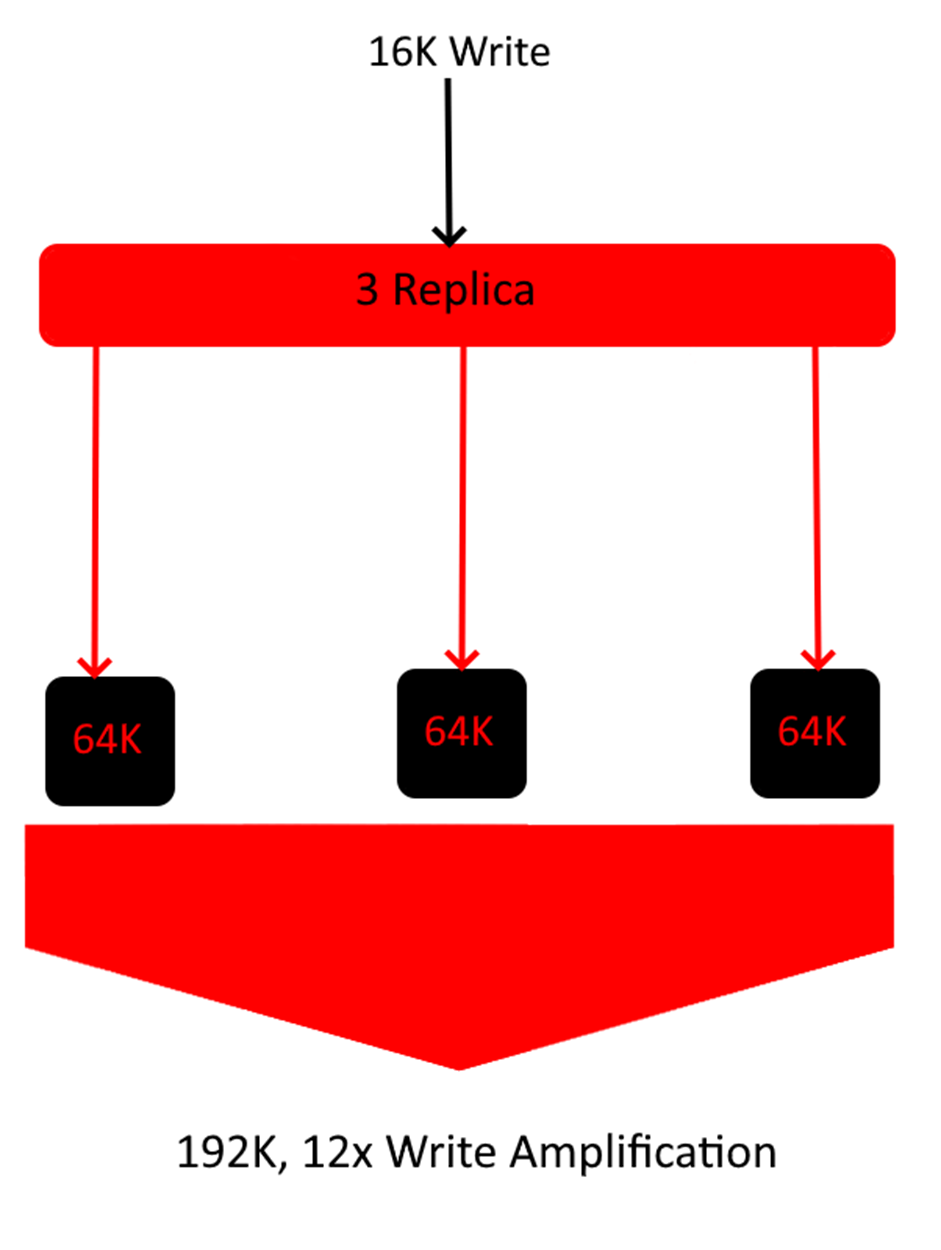
As you can see in the above diagram, in this specific workload, 3 Replica is actually more storage efficient than the 4+2 Erasure Coding Pool. This shows that there are always exceptions to rules. Theoretically, erasure coding should be used when storage efficiency is the highest priority, but depending on your dataset, this can shift drastically.
Of course, 16K files are small even by small file workload standards, for reference just this blog post alone is almost 100K. But a few examples of use cases that could have write amplification issues are:
Understanding your data and workload are crucial parts in determining the build of your Ceph cluster. Having an understanding of average file sizes throughout your data will allow you to avoid this extremely high write amplification.
Of course, this isn’t always black and white. Often, you will have a range of file sizes throughout an environment. In which case, it’s simply a matter of determining where that data is. For example, if a single directory tree possesses the majority of your small files, you could pin a replica pool to that specific tree, while the rest of your data with larger file sizes remains on Erasure Coding.
As mentioned earlier write amplification is much more prevalent when your minimum allocation size is too large, this is why newer versions of Ceph such as Pacific and Quincy default to 4K rather than 64K. In newer clusters, or Octopus clusters with a modified minimum allocation size, write amplification is much less of a concern, but it’s still definitely worth considering in your next Ceph deployment!
Newsletter Signup
Sign up to be the first to know about new blog posts and other technical resources