Some people think Ceph is difficult, with a steep learning curve and a complicated maintenance process. But that’s not the case. Ceph has come a long way in terms of simplicity and usability. It also has a number of tools to make deployment and maintenance a relatively pain-free task.
Ceph is open-source clustering software which links multiple servers together into a single unified storage system. Storage systems built on Ceph can be extremely robust and resilient. Ceph can provide excellent block, file and object storage.
To answer the question, no, Ceph is not difficult.
There are a number of tools and advancements made with Ceph over the years to simplify deployment, management and maintenance. The biggest factor that ensures Ceph’s simplicity is its resiliency and robustness.
Ceph is able to withstand failures in a way that is impossible in a single server. A properly configured Ceph cluster can withstand entire servers failing and remain online and functional. Due to linking multiple servers into a single unit, Ceph provides redundancy and eliminates single points of failure. Through this method, Ceph is able to ensure uptime that otherwise wouldn’t be possible (this is called high availability).

Ceph’s highly-available nature allows administrators a much less stressful time managing their storage. Let’s face it; it’s not very fun working during off hours because your server has gone offline or you need to perform maintenance. Ceph can stay online during maintenance or in the event that there is a large failure. This is not possible in a single server.
High availability can also be critical to certain use cases, like retail stores, where storage being offline means payment can’t be processed. Ceph is also very accessible financially and can easily pay for itself in those cases.
Single servers are great for certain use cases but can’t provide certain advantages that a well-configured cluster provides.
When updating, a single server will have some amount of downtime. These updates are traditionally performed during off hours. Single servers may also have downtime if hardware fails. It is much less stressful if drives start falling offline in a Ceph cluster compared to a single server.
Ceph clustering gives you the ability to start small and continually grow your capacity over time. Single servers are limited by drive slots in a server, which will eventually force you to implement additional systems. This can lead to a sprawl across your network, which we at 45Drives like to call a “server zoo.”
Ceph can scale practically infinitely in capacity, all while remaining in the same unified system. Namespaces are defined in software which allows management flexibility. In addition, Ceph clusters don’t only scale in capacity but will also scale in performance as more resources are added to the cluster.
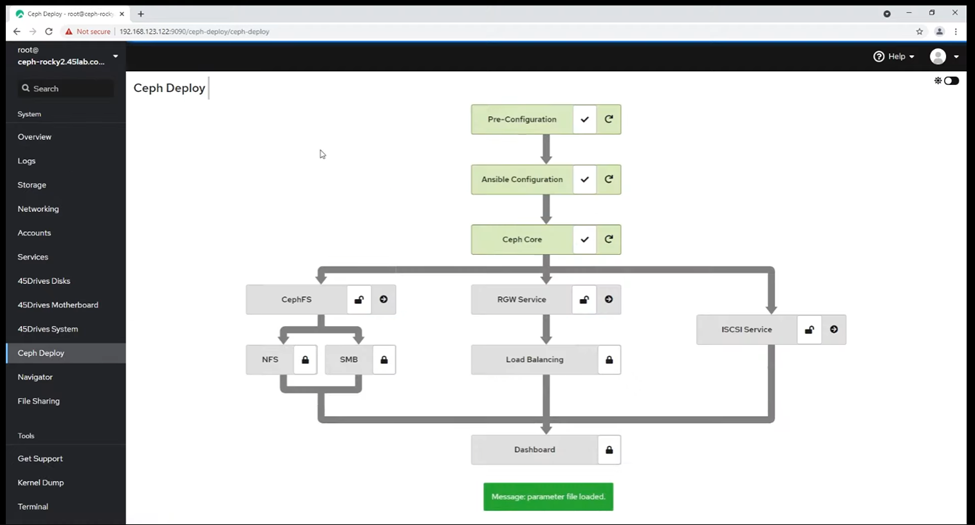
Ceph Deploy is a module of the Houston command center. It makes setting up and deploying a Ceph cluster a breeze through a graphical interface. Under the hood, it uses Ceph Ansible. Unfortunately, it only works on 45Drives machines because of how it aliases and identifies the drives (fortunately, it is free from licensing fees). Still, for those who can leverage it, it simplifies the setup and deployment phase significantly.
There are also hardware-agnostic Ceph tools which can help simplify the deployment phase.
The Ceph dashboard and Houston Command Center combine to make managing a Ceph cluster a very simple task. First, let’s break down what those are.
The Ceph dashboard is a clean and organized view of your cluster’s health. At first view, it includes alerts, the general health status of the entire cluster and key services such as monitors and disks. The Ceph dashboard also provides access to embedded Grafana graphs, a configuration editor and OSD management. All-in-all, the Ceph dashboard provides a great platform for managing cluster-level tasks.
Houston is an offshoot of the Cockpit project developed by 45Drives. It is a server management layer, meaning it doesn’t work directly with Ceph (the one exception being the Ceph deploy module). Instead, Houston provides a graphical way of performing server-level tasks, like identifying failed drives. You can read all about Houston’s capabilities here.
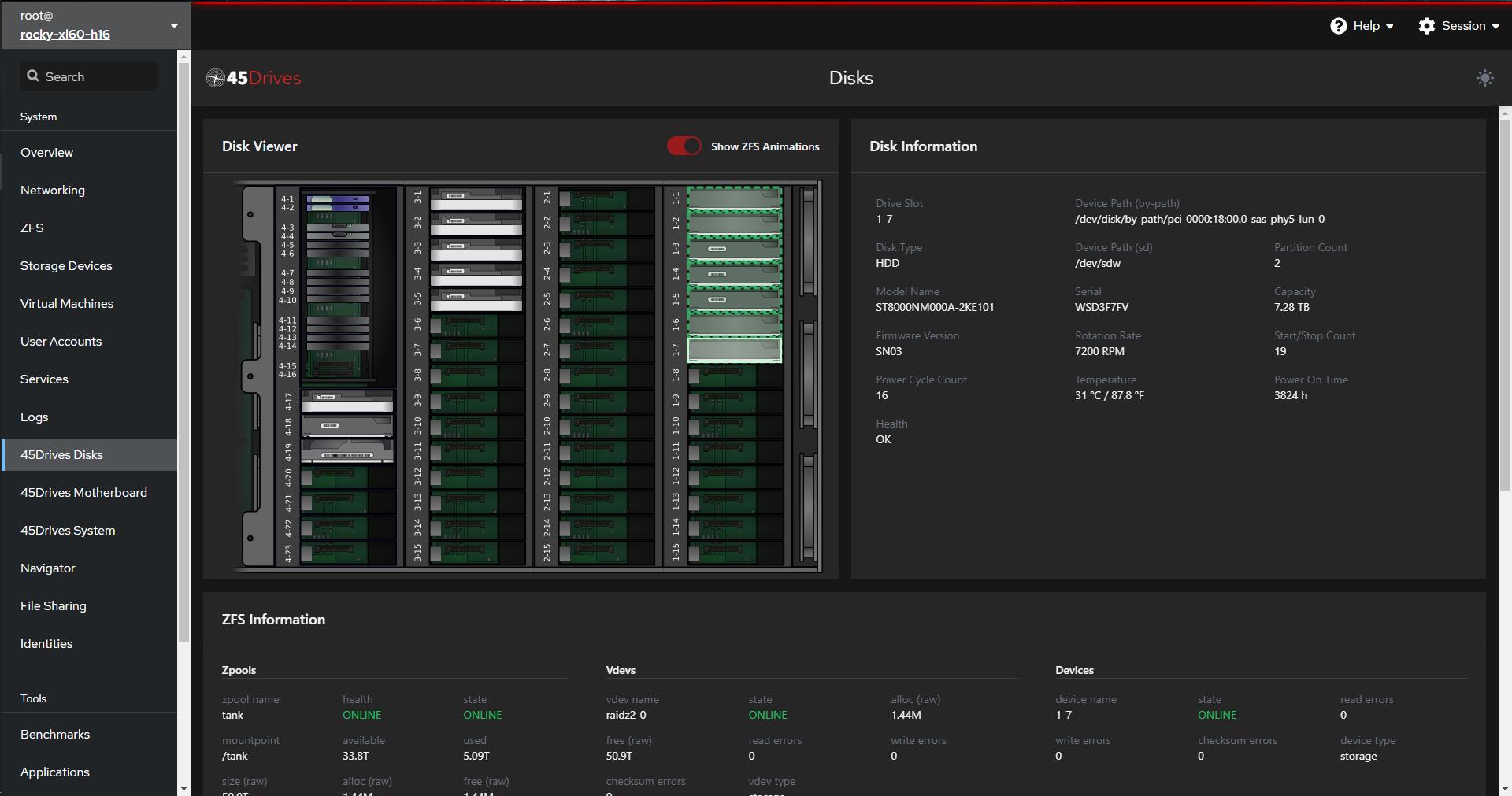
The Ceph dashboard is excellent for managing cluster-level tasks, whereas Houston will make things like server-level tasks extremely easy. By leveraging both tools, you can make Ceph cluster management a simple, pain-free task. Ceph management doesn’t need to be difficult.
The Ceph deploy module in Houston is the only area where this distinction gets slightly fuzzy. 45Drives developed a Houston module which leverages Ceph Ansible to deploy Ceph clusters in the simplest and most robust method available. This exists within Houston, not within the Ceph dashboard.
45Drives is here to assist your organization with any clustering project. We offer full-scale enterprise support that can give your team confidence in the transition to Ceph clustering. If there is ever an issue with your Ceph cluster, the 45Drives team of storage experts is here. We will ensure your system will be back up and running as quickly as possible. Even before you begin your storage project, 45Drives offers consulting on your storage infrastructure.
“We were in the market for moderate performance high-capacity storage solution. We searched through the market and came to 45drives after they were found to be the right fit for our needs. We purchased 4 of the 45-drive models and are currently expanding the capacity of the cluster again after only two years! Very happy with the product, and the support that we’ve received from the team at 45drives.com”
Kevin Schretlen – University of Northern British Columbia
For those who prioritize bringing their team up to speed as quickly as possible, 45Drives offers a Ceph training bootcamp. The bootcamp will provide your team with a deeper understanding of Ceph and the expertise to maintain critical systems in high-stress incidents – if they ever occur. You will also be certified by 45Drives Senior Storage Architect.

Ceph’s resiliency comes from eliminating single points of failure. With a single server, it is impossible to remove single points of failure, as, at the end of the day, the server itself can be a failure point. Ceph will have multiple redundant copies of everything. This protects you from your average drive failure(s) like a raid array in a single server but makes it much less of a problem. Once drives start failing in a Ceph cluster, Ceph will begin self-healing to bring your cluster back to a balanced and healthy state. When drives begin failing in a single server, it can be dangerous because additional failures can put you at risk of losing your pool.
Ceph also can stay up during maintenance, for example, updates. Compared to single servers, where you are likely facing downtime.
In addition, Ceph has a number of tools that have made it simpler than ever to access.
Contact 45Drives today to figure out how to use Ceph in your next storage project.
Newsletter Signup
Sign up to be the first to know about new blog posts and other technical resources